



電流倍增器:為 AI 處理器及其他嚴苛應用供電的明智之選
AI 處理器需要解决低電壓、高電流的嚴苛挑戰,這將會導致電源系統設計產生瓶頸。瞭解 Vicor 的電流倍增技術如何改變這一現狀
隨著 AI 訓練模型生成的資料量激增,處理能力已經無法滿足需求。為了在不超出能源預算的情况下實現最高的運算效能,資料中心需要一種新的供電方法。瞭解 Vicor 的垂直供電為何是當今機器學習領域最有效的方法。
Vicor 公司戰略營銷副總裁 Maury Wood 訪談錄
生成式人工智慧(genAI)越來越受歡迎,但其對運算週期的需求非常大,需要大量電力。應對大規模生成式人工智慧的電力需求極具挑戰性。《電子設計》(Electronic Design)雜誌編輯 Bill Wong 與 Vicor 公司的戰畧行銷副總裁 Maury Wood 進行了對話,深入探討了這些挑戰和解決方案。
OpenAI 於 2022 年 11 月推出了 ChatGPT,生成式人工智慧帶來的文化影響(以及預期的未來影響)非常大,最終將觸及人類活動的各個方面。 從技術角度來看,有一點越來越清晰:生成式人工智慧模型訓練將帶來最高的運算效能、存儲容量和網路頻寬。
生成式人工智慧正在推動電晶體、基礎設施硬體和系統軟體以及網路邊緣領域的大量新投資。這些投資活動預計將擴充到車輛、家庭和工作場所的嵌入式 AI 設備中。
目前,生成式人工智慧訓練處理器使用大量電晶體(多達 1000 億甚至更多),採用 4-nm CMOS 芯粒等先進技術,這些電晶體在運行時會漏電。儘管這些電晶體的供電電壓低至 0.7VDD,但持續電流需求可能達到 1000A 或更高,這意味著持續功率(也稱為熱設計功率)達到 700W。峰值電流需求可能高達 2000A,相當於短時間內的峰值功率達到 1400W 甚至更高。
相比之下,生成式人工智慧推理所需的功率要少得多。一個很好的經驗法則是,推理能耗大約是訓練同一大型語言模型(LLM)的能耗的平方根(圖1)。

圖 1:生成式人工智慧訓練處理器峰值電流需求的演變。
這個問題的難點在於電流需求的高度瞬變,具體取決於訓練處理器的算法負載。換句話說,隨著神經網路模型任務負載的新增或减少,電流需求會有劇烈波動,每微秒變化甚至可達 2000A。
此外,為了避免電晶體在這些頻繁的瞬變過程中受損,任何電壓過沖或欠沖必須限制在 10% 以內(即 0.7VDD 時為 0.07V)。這對傳統的供電架構來說極具挑戰性。
直到最近,資料中心一直使用 12V 直流電源。過去十年中,Vicor 一直宣導在資料中心機架中使用 48V 直流電,因為根據歐姆定律,更高的電壓意味著非零電阻導體中的功率損耗更低。Open Compute Project 製定的 Open Rack 規範大大推動了 48V 直流電在高效能運算應用中的採用。
在早期的生成式人工智慧供電架構中,標稱的 48V 直流電源在加速模組中被轉換為中間母線電壓。這種中間直流訊號通常饋入多相跨電感穩壓器(TLVR),但這種方法在可擴充性和電流密度方面存在硬性限制。
在用於生成式人工智慧訓練處理器的加速模組(AM)中,印刷電路板(PCB)上的空間非常有限,這意味著這些處理器的供電子系統的功率密度(W/mm²)和電流密度(A/mm²)必須非常高。傳統的電源根本無法達到要求,既不能提供所需的電流,也無法適應可用的 PCB 空間。
如前所述,生成式人工智慧訓練處理器的電源組件必須滿足負載階躍瞬變引起的動態效能要求。同樣,傳統的供電方法也不適合這些需求,特別是因為生成式人工智慧訓練處理器需要大約 3mF 的去耦電容盡可能靠近處理器封裝(圖 2)。
圖 2:這個概念性的生成式人工智慧加速模組展示了生成式人工智慧處理器,支持使用芯粒封裝的高頻寬記憶體(HBM)。
此外,生成式人工智慧供電架構中的組件必須具有很强的熱適應性。無論生成式人工智慧系統是液冷還是風冷,電力組件都必須具有高熱導率,並且其封裝應能够在其生命週期內承受極高的熱循環。
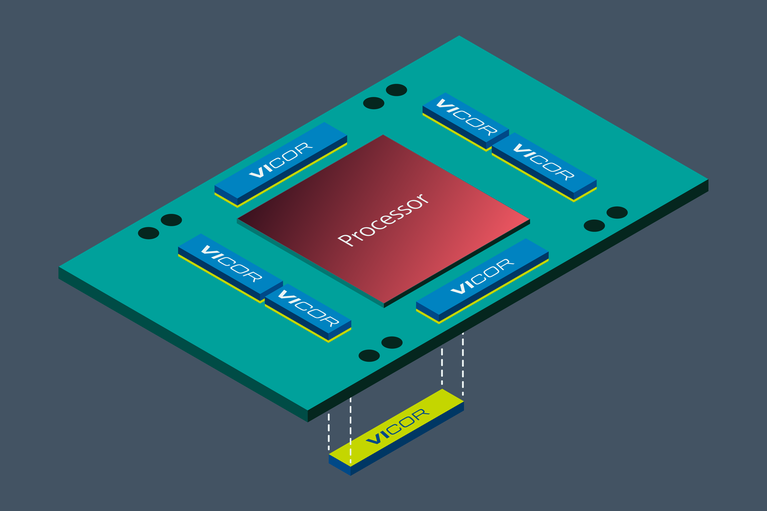
更新的生成式人工智慧加速模組(AM)使用分比式電源架構,負載點轉換器利用電流倍增科技,例如 Vicor 的創新技術。
優化負載點電源組件的物理位置,是降低生成式人工智慧的功耗,同時提高供電質量的一種重要方法。將最終階段的這些電源組件從橫向放置改為垂直放置在生成式人工智慧處理器的正下方,可以降低 PCB 本身的功耗。由於電流密度約為 3A/mm²,負載點電流倍增器可以共亯生成式人工智慧訓練處理器下方的有限空間。
這種 PCB 熱功率减少是因為與純橫向放置電源組件相比,垂直供電(VPD)網路的總阻抗减少了多達 20 倍。
目前,最大的生成式人工智慧訓練超級電腦包含多達 2 萬個加速模組。值得注意的是,NVIDIA 的資料顯示,OpenAI 的 GPT-3 模型有 1750 億個參數,需要大約 300 zettaFLOPS(即每秒 1021 次浮點運算),這意味著在整個模型訓練週期內需要進行 30 萬億億次數學運算。而且,這些模型的規模只會繼續新增,目前正在開發的神經網路模型使用的參數已達到萬億級。
Vicor 估計,與傳統的 TLVR 橫向供電相比,分比式 VPD 可以將每個加速模組的功率降低大約 100W(記住,AI 超級電腦基本上是永久通電的,幾乎從不關閉)。
通過合理預測 2027 年全球運營的生成式人工智慧資料中心的數量,Vicor 估計總共可以節省數太瓦的電力,相當於每年可節約數十億美元的電費,减少數百萬噸的二氧化碳排放,具體取決於可再生能源的使用比例(圖 3)。
圖 3:加速模組中垂直放置的電力組件有助於最大限度地减少 PDN 損耗。
多相脈寬調製(PWM)降壓調節可以被理解為電流平均化,就像通過動態地混合熱水(全峰值電流)和冷水(無電流)來形成溫水一樣。而 Vicor 的分比式電源架構構則完全不同,可以理解為用高效的電壓分配來實現電流倍增。
封裝在 ChiP™ 產品中的模組化電流倍增轉換器與 PCB 板佈局相容,無需大量工程修改即可實現各種電流水准。
這種業界領先的供電架構結合了最先進的正弦振幅轉換器(SAC™)電路拓撲。該拓撲使用零電壓開關和零電流開關方法來最小化開關雜訊和雜散輻射,並最大限度地提高 DC-DC 轉換效率。MOSFET 高頻開關减少了高度集成模組的物理尺寸。這些設計元素與先進的組件和封裝相結合,以應對下一代 AI/HPC 的供電挑戰。
台積電(TSMC)等領先的電晶體製造商已經公佈了未來兩到三個工藝節點(2nm、1.6nm)的技術路線圖,這些節點採用全新的 CMOS 創新技術,如全栅納米片或納米線電晶體。這些器件在物理設計方面的改進以及芯粒封裝技術的加速應用,將繼續推動生成式人工智慧處理器電流水准不斷提升。
在算法開發方面,可以肯定的是,主要的大型語言模型(LLM)開發商如 OpenAI、微軟、谷歌、Meta 和亞馬遜等將繼續推進多萬億參數的神經網路模型,這將需要更高的運算、存儲和網路通訊頻寬。
毫無疑問,在可預見的未來,生成式人工智慧將繼續成為現代運算世界中功耗最高、散熱最具挑戰的應用。Vicor 將繼續創新,抓住這一令人興奮的新商機,滿足不斷增長的供電需求。
是的,主要原因在於,我們可以合理地預期企業和個人將在中長期內需要大量的推理頻寬。許多甚至大多數生成式人工智慧應用程序將使用預訓練模型,並通過提示工程進行定制。與推理週期相比,訓練週期相對較少(頻率低很多個數量級)。
雲服務提供者(CSP)將尋找成本最低的推理解決方案。這些解決方案需要支持整數和向量指令(浮點乘加運算)。
CSP 希望盡可能多地同時運行推理任務,推動其處理器架構選擇高核數、高頻寬的運算引擎,追求每瓦特數萬億次運算(TOPS)的效能指標。高頻寬推理處理器應運而生,其中一些處理器的熱設計功耗(TDP)高達 500W。我們預計這一趨勢將持續並加速發展。
過去幾年發佈的所有生成式人工智慧訓練處理器都採用了芯粒封裝技術。利用異構邏輯和存儲芯粒,處理器開發人員得以突破 Dennard 縮放和摩爾定律的邊際效益遞減。這兩個定律在過去 70 年間共同推動了電晶體製造技術的進步,將特徵尺寸從 20mm 减小到了 2nm。
生成式人工智慧芯粒解決方案通常在一個基板上結合高頻寬存儲(HMB)設備與圖形處理單元(GPU),採用又寬又快的母線連接。台積電最近公佈了 2.5D、3D 的 CoWoS 封裝技術(a chip-on-wafer-on-substrate)路線圖,其目標基板尺寸是 120×120mm,預計電流消耗將達數千安培。Cerebras 的 CS-3 和特斯拉的 Dojo D1 等最新的晶圓級生成式人工智慧訓練處理器分別消耗約 23kW 和 15kW。
在可預見的未來,生成式人工智慧處理器的功率水准似乎將繼續快速增長。
本文最初由 Electronic Design 發表。


